
焦点分析
- 中国人工智能的发展势头正日益体现在其应用普及与经济性上——大规模普及叠加“成本断崖式下降”,让人工智能成为日常的通用型工具。
- 与美国相比,中国人工智能的优势体现在开源策略、政府主导布局,以及在融资与容量建设上的务实做法。
- 在中国更广泛的系统性人工智能加速的背景下,个股投资机会众多,行业正强势转向聚焦可量化投资回报率(ROI)的智能体应用场景。
2026年,中国人工智能发展叙事正从“追赶”转为“竞争”,部分领域甚至已领先于全球。2025年初,DeepSeek发布R-1模型,直接对美国在人工智能领域的领先优势构成挑战,并向世界发出强烈信号:中国有能力以远低于OpenAI(旗下产品ChatGPT)等美国公司的成本,开发出最先进的人工智能模型。当时,该事件一度令 NVIDIA 市值蒸发约 6,000 亿美元。1
在中国收视率最高的春节联欢晚会上,人形机器人与人类演员同台共舞并表演武术,节目之精彩令世界惊叹,也再次展示中国在人工智能领域已跻身全球领先行列,并可与美国及中东地区相提并论。对比去年春晚上的类似节目,人们会发现,与仅仅一年前展示的简单动作相比,机器人如今的表演已实现了质的飞跃。
同时,近期举行的中国“两会”全文公布了2026年-2030年的“五年规划”,再次突显中国日益重视以科技和创新驱动增长和提升生产率的战略决心。这一战略由新的目标作为支撑:中国计划实现研发经费投入年均增长7%以上;到2030年,数字经济占GDP的比重从10.5%提高至约12.5%,同时维持劳动生产率增长高于GDP增长。2
中国正成为人工智能规模化普及的重要推动力量
春节前后,多款主流人工智能模型相继发布(字节跳动Seedance 2.0、阿里巴巴通义千问3.5、智谱GLM-5、月之暗面Kimi K2.5相继亮相,另外MiniMax于3月推出了M2.7,DeepSeek的V4也将于4月发布)。各公司借春节契机,推动人工智能普及与认知度提升达到拐点。通过游戏化“红包”(春节期间互发现金的传统习俗)活动,以及在日常应用和电信服务中内嵌人工智能功能,数亿用户获得了体验人工智能的便捷机会。
例如,中国电信将大语言模型直接集成到手机网络中。低线城市用户无需掌握任何提示词技巧,即可生成用于春节拜年的“人工智能视频彩铃”。我们认为,这正是人工智能的“红包时刻”,如同2014年腾讯微信借助红包功能让移动支付走向普及一样。当年微信“电子红包”功能一经推出便迅速风靡,用户纷纷以此替代现金红包馈赠亲友。这也是移动支付首次被更广泛的用户群体大规模采用,包括非城市地区和老年群体。
规模化应用有望在消费级人工智能领域迅速催生“赢家通吃”的市场格局,尤其当成熟企业能够将人工智能整合到其支付、电商、社交和视频创作等现有生态系统中时更是如此。春节过后,真正的角逐才刚刚开始。最终赢家并非派发红包最多的公司,而是那些能够留住这些新用户的企业。
整体来看,字节跳动在人工智能与消费者互动方面处于领先地位。阿里巴巴正快速追赶,腾讯及其他现有互联网巨头同样不甘落后,依托自身成熟生态系统留住用户。
最新人工智能模型的发布展示出中国在多项技术上实现突破:
在视频生成技术上占据领先地位
字节跳动继2025年6月低调推出Seedance后,于2026年2月发布了性能大幅提升的Seedance 2.0。该模型可融合文本、图像与音频,以显著更低的成本生成影院级画质的短视频。目前Seedance 2.0在视频生成技术上占据领先地位,多项指标的表现均优于OpenAI的Sora 2与谷歌的Veo 3。3这是中国模型首次在主要多模态赛道(即同时理解和处理文本、图像、音频及视频等多种信息的能力)上占据首位。
“智能体”革命
行业关注点已从聊天机器人转向智能体——即能够完成实际工作的人工智能。随着智能体人工智能时代的到来,成功的衡量标准变得更具体,可通过投资回报率(ROI)、成本削减及其他运营效率指标进行评估。
以下是与美国同业竞争力相当的中国人工智能技术创新示例:4
- 智谱(GLM-5)在编码与智能体能力上达到开源领域最先进水平(SOTA),被认为与Anthropic的Claude 3.5 Sonnet性能相当。
- MiniMax(M2.5)推出全球首个原生智能体模型(智能体大语言模型)(100亿参数),专为高效执行复杂任务设计。
- 月之暗面(Kimi K2.5)实现了与OpenAI o1模型相当的推理能力。
成本断崖式下跌
智能体工作流的成本大幅下降。短短几周前,API调用(允许一个应用程序向另一个应用程序请求数据或服务)每月仍需花费300美元,如今通过国内开源模型实现同类功能,成本仅为原来的一小部分。这推动人工智能从“高端奢侈品”真正转变为日常工具。
图1:中国人工智能(智谱-GLM)与美国同类产品(Anthropic-Claude)的成本对比
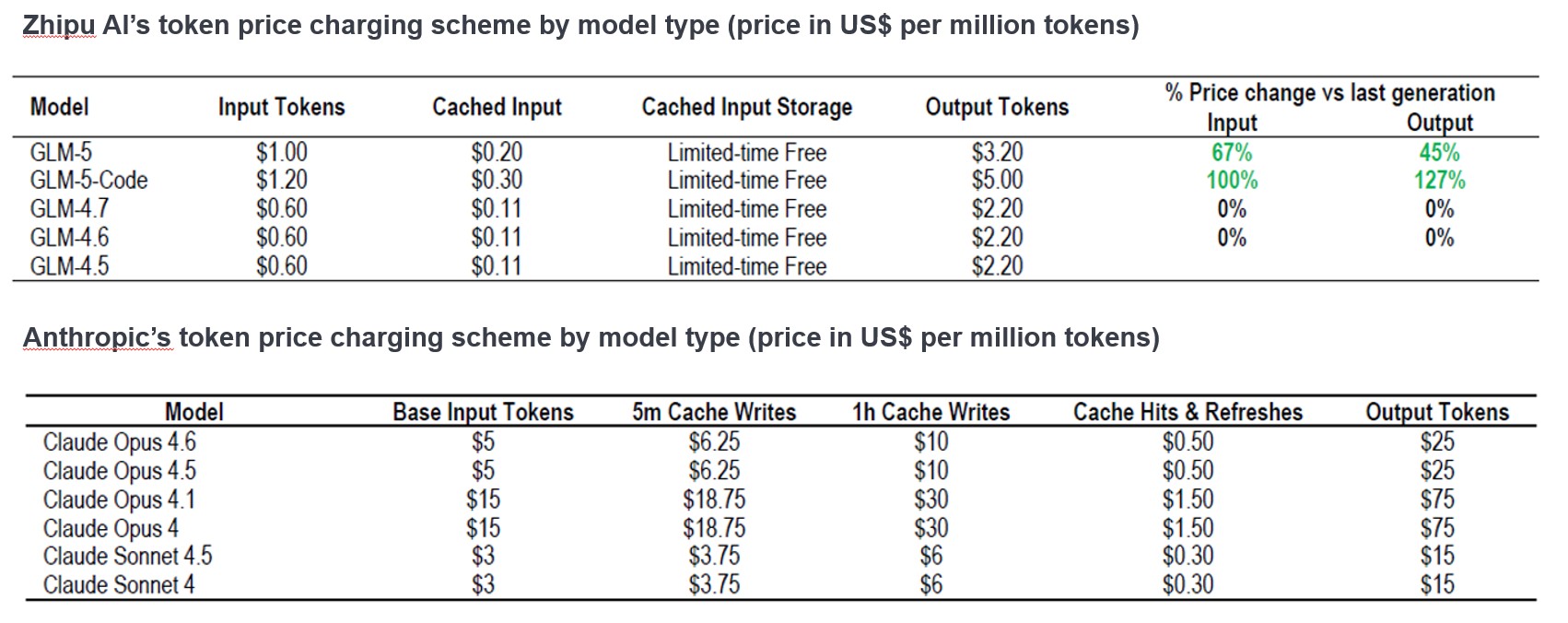
资料来源:摩根大通;《中国人工智能》,亚太股票研究团队;2026年2月9日。
中美人工智能对比:策略各异,优势不同
2025年初的“DeepSeek”时刻带动多只中国人工智能概念股估值重估,但市场对人工智能泡沫的普遍担忧,令部分企业全年股价承压。不过,进入2026年以来,随着投资者对中国人工智能初创企业技术能力与增长潜力的信心持续增强,部分人工智能公司股价大幅反弹。2025年8月政府推出的“人工智能+”政策也提供了有力支撑,该政策旨在推动人工智能在科技、产业发展、消费、民生、治理等各领域实现广泛深度整合。
我们认为,中国在人工智能竞逐中具备四大竞争优势:
1.开源模式
美国市场以闭源模型为主,用户无法查看、修改或再分发大语言模型源代码,且通常需遵守许可协议。相比之下,中国则积极将开源作为竞争策略。通过开源如阿里巴巴的通义千问和DeepSeek等强大模型,中国企业正在构建庞大的全球用户社区。这形成了技术迭代飞轮效应——全球成千上万的开发者共同测试、修复与优化模型,速度远超任何单一闭源实验室。加之中国的词元价格仅为美国词元的零头水平,这意味着企业与个人可快速普及应用高性能推理能力。
近期,OpenRouter5的数据显示,受开源运营平台OpenClaw用量激增影响,2026年2月的词元消耗量大幅攀升。这款免费开源的自主人工智能体,通过接入WhatsApp、微信、微软Teams、Telegram及网页浏览器等应用,让用户不再局限于只能与人工智能聊天,而是能够用其“完成工作”(如日程管理、发送邮件、查询航班等)。
OpenClaw使用量排名前三的人工智能模型均来自中国,与同期多款高性能且高性价比模型发布相契合,这包括月之暗面Kimi K2.5(2026年1月)、MiniMax的M2.5(2026年2月)以及智谱的GLM-5(2026年2月)。3尽管谷歌Gemini 3在成功率方面排名最高,但OpenClaw创始人Peter Stringer特别指出,从成功率、速度与成本综合考量,MiniMax M2.1是更值得推荐的大语言模型。4
图2:按成功率排序的全球前十位大语言模型(2026年3月8日)
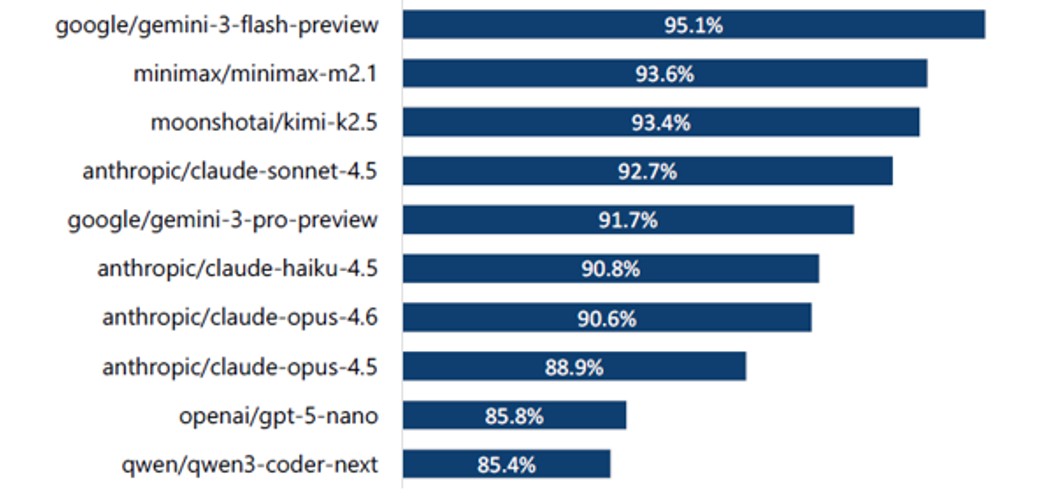
来源:杰富瑞(Jeffries)股票研究:中国互联网;PinchBench,杰富瑞数据;2026年3月12日。
2. 关注商业化变现
与美国竞争对手相比,中国人工智能企业的融资渠道(以及量级)较有限,高端芯片供给同样受到约束,因此他们往往更注重商业化变现。中国的人工智能生态呈现出极为务实的导向:行业重心正从理论指标转向即时的商业应用落地。
除消费级聊天机器人外,中国正将人工智能更广泛地应用到各行各业。将人工智能应用于工业流程,例如质量控制或供应链优化等场景,难度远高于开发聊天应用。这类应用的落地需要时间,且必须与硬件和真实业务数据深度整合。然而,一旦成功落地,其创造的价值将十分巨大且往往具有粘性。而凭借其“世界工厂”的地位,中国在这一领域相比其他国家拥有显著的数据优势。
3. 政府主导的基础设施建设
中国正在发挥自身最擅长的优势:以更快速度和更低成本建设基础设施,包括电力供应、芯片、数据中心及先进制冷系统等。中央与地方政府正加紧布局人工智能所需的基础设施,尤其是在太阳能和风能资源丰富的中国西部地区建设数据中心。这种政府主导的模式可以加快大型基础设施的建设,包括人工智能集群所需的电网升级和电力分配。
4. 产能过剩风险有限
由于中国资本市场融资环境更为紧缩(融资成本高于西方国家),长周期项目的融资并未出现非理性的狂热。资本流动更为理性,使得产能过剩的风险相对美国明显更低。
投资机会:超越显而易见的“人工智能赢家”
除中国互联网巨头、半导体及硬件企业外,投资者也可以关注更广泛的中国人工智能全生态系统,以实现人工智能领域的多元化配置。举例而言,在人工智能基础设施领域,在中国建设数据中心需遵守复杂的国家能耗与土地使用监管规定。万国数据(GDS)和世纪互联(VNET)等企业已持有相关牌照及电力配额,并拥有良好的政府合作关系,能够有效推进项目落地。MiniMax和智谱人工智能等单纯人工智能业务公司,正逐步将其应用程序接口(API,允许软件之间相互通信)业务面向全球开发者实现规模化拓展。相关业务的收入结构与利润率,有望在内存与半导体供应链、自动驾驶、人形机器人相关技术及应用等领域快速增长。
结论:中国人工智能的拐点由应用与规模化驱动,而非仅靠模型
我们认为,中国当前正经历一场更广泛的系统性人工智能加速:通过消费平台实现大规模普及、依托开源生态系统实现快速迭代,并强势转向聚焦可量化投资回报率(ROI)的智能体应用场景。这对投资者至关重要,因为人工智能的应用——而非单纯的模型能力——往往决定了利润归属。
尽管短期内中国经济仍面临挑战,包括全球宏观不确定性加剧、房地产行业疲软以及国内消费乏力等,但国内外投资者对中国长期前景的看法正变得更为积极。风险依然存在,但我们认为,政府以人工智能提升生产率的政策重点、宽松的货币政策、中美关系缓和以及有利的汇率环境,共同构成了优质选股的肥沃土壤。
倘若英文版本与中文版本出现歧异,概以英文版为准。
1 BBC新闻;中国的DeepSeek震惊了市场,但它是否改变了人工智能格局?2025年8月10日。
2 摩根士丹利研究;中国思考;2026年3月10日。
3 https://aitoolsreview.co.uk;LantaAI评估;2026年2月17日。
4 摩根大通研究;中国人工智能;2026年2月9日。
5 杰富瑞(Jeffries)股票研究:中国互联网;数据来自OpenRouter、杰富瑞;2026年3月12日。
原生智能体大语言模型(或称智能体大语言模型):指专门设计用于充当自主智能体“大脑”的大语言模型,而非仅作为被动的文本生成工具。与标准大语言模型不同,这类模型在推理、规划、工具调用以及与外部环境交互完成多步骤任务等方面经过专项优化。
API(应用程序接口):供开发者将人工智能集成到软件产品中的接口。
资本支出:指为维持或改善运营并促进未来增长而购买或升级建筑物、机械、设备、或工具等固定资产的支出。
闭源模型:一种专有模型;用户通过受控的API或相关产品使用该模型。
推理:指人工智能处理过程。机器学习和深度学习指训练神经网络,而人工智能推理是应用经过训练的神经网络模型的知识,从而推断结果。
LLM(大型語言模型): 一類專門的人工智能,利用大量文本進行訓練,以了解現有內容並生成原始內容。
模型即服务(MaaS):通过API出售人工智能访问权限,通常按使用量计费。
多模态人工智能:能够处理多种输入与输出类型(文本、图像、音频、视频)的人工智能。
开源模型:指模型权重(核心参数)对外公开,可供他人运行和修改的模型。
ROI(投资回报率):用来衡量投资业绩的财务比率,计算方法是将净利润/亏损除以投资的初始成本。
词元(token):人工智能标记是大语言模型(LLM)在输入和输出过程中使用的基本构建单元。它们是大语言模型用来处理和生成有效文本/输出的最小数据单位。
利用率:数据中心的容量被客户实际使用的比例。