
焦点分析
- 人工智能创新持续加速,代理式人工智能正接近关键拐点。推理模型与人工智能体(AI agent)正在扩展应用场景并显著提升算力需求,但这也引发了关于资金投入与回报之间关系的争论。
- 与互联网时代相比,当前的资本支出相较于以往的技术周期似乎更具可持续性。同时,一些被视为循环融资(即不可持续的融资模式)的领域,实际上得到了超大规模云服务提供商资产负债表的支持,而不仅仅是投机性融资。
- 在这个“赢家占优”的格局中,主动型投资至关重要——既要发掘未来盈利增长被低估的企业,也要有效规避关键风险。
人工智能持续发展
当我们谈论人工智能时,这是一个动态发展的议题。一年前DeepSeek发布后,我们认为这标志着更智能、更强大且成本更低的推理模型开始崭露头角,这将推动人工智能应用迈向新高度。但这需要十倍于当前的算力支撑——因此,与DeepSeek发布后算力需求将减少的市场共识相反,我们断言实际需求将呈指数级增长。到2025年底,推理模型处理的词元(token)量占比已从年初的零攀升至50%以上1,与此同时,人工智能领域的资本支出再度显著提升。
图1:推理模型现已占词元使用量的半数以上
推理与非推理词元随时间的变化趋势
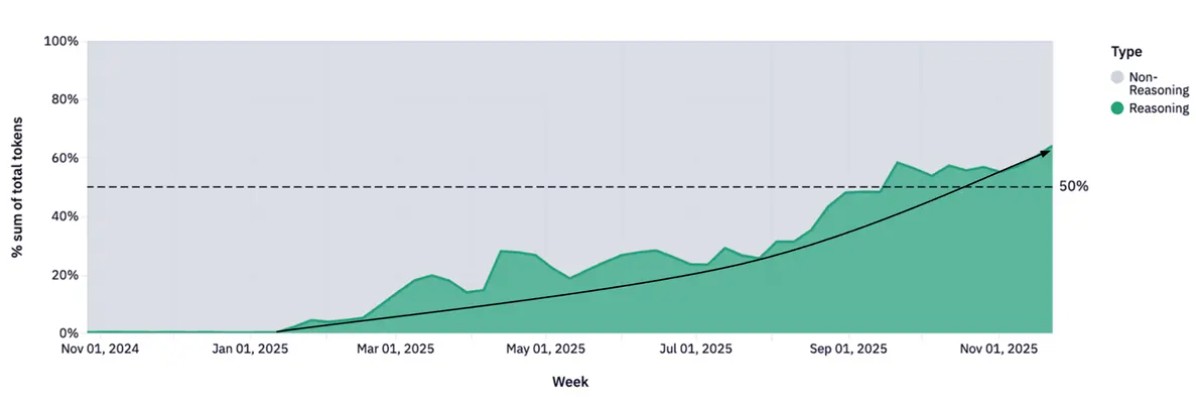
资料来源:Openrouter.AI;基于OpenRouter的100万亿词元实证研究;2025年12月。
代理式人工智能正接近拐点
我们认为,代理式人工智能(自主决策与执行)的下一个重大拐点即将到来——它在数字世界以人工智能体的形态显现,在物理世界则体现在自动驾驶汽车和人形机器人的发展上。多项重大技术突破正汇聚融合,有望推动人工智能创新加速而非放缓。人工智能编程智能体据称现已超越人类能力,并正在加速大语言模型的发展曲线——正如Anthropic首席执行官Dario Amodei在近期发表的一篇文章中所强调的那样。2此外,从2026年中期起,我们将很快见证基于最新Blackwell基础设施训练的大语言模这能够大幅加快编程与计算速度,为创新曲线的加速奠定基础。迄今为止,包括Gemini 3和ChatGPT 5.2在内的所有大语言模型,均基于NVIDIA的Hopper芯片系列进行训练。待到最先进的Vera Rubin Ultra芯片(预计2028年推出)所训练的大语言模型面世时,人工智能基础设施的处理速度可能提升约400倍,从而实现训练进程和反馈循环的指数级加速。3
图2:人工智能发展拓展应用场景
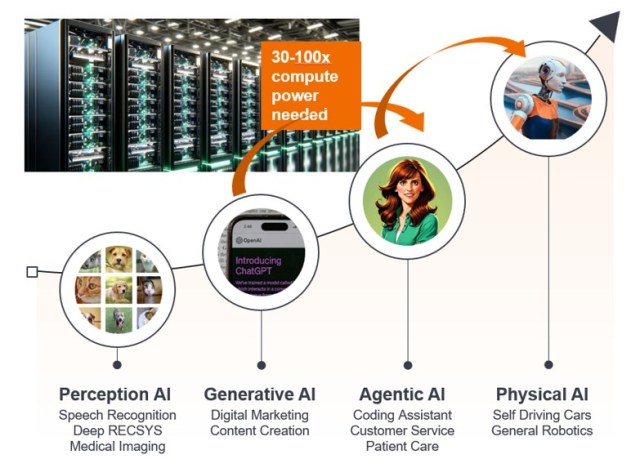
资料来源:骏利亨德森投资。
代理式人工智能时代即将来临
更快的人工智能发展曲线将呈现何种形态?我们关注的重点领域依然是代理式人工智能——这类人工智能体能够模拟人类决策过程,实时解决问题,鉴于其能够脱离人类监督与约束,因此能力远超智能助手。推理模型及各类人工智能体面临的挑战在于上下文窗口和思维链的时限,也就是说,人工智能体如同患有短期记忆丧失的人类,虽能快速运作,却会很快遗忘自身目标。业界正通过持续大量创新着力解决这一问题,一方面拓展上下文窗口(Google Gemini率先实现一百万词元处理能力,相当于1,500 页文本量)4,另一方面运用多种技术延长思维链,从稀疏混合专家系统到强化学习,乃至引导智能体在现实环境中行为的智能体约束系统。
人工智能处理长期任务的能力似乎约每七个月翻一番。正因如此,Anthropic指出其编程智能体在短短三年间,从几乎无法编写代码发展到超越公司最优秀的程序员,同样也让 “人工智能正在吞噬软件行业”这一叙事成为投资者的关注点。这一趋势的重要性在于人工智能体能够带来的潜在生产力提升。麦肯锡(McKinsey & Co.)曾提出构建约65,000人的“劳动力队伍”,其中包含40,000名人类员工和25,000个智能体。5与人类劳动力不同,智能体的部署数量不受人口因素限制。据估计,若按发展曲线推算,人工智能体可能在2028年可靠地完成人类单日的工作量,到2034年可实现一日完成人类一年的工作量,至2037年更可能在一日内完成人类一个世纪的工作量——这将对白领职业及相关产业产生深远影响。
物理人工智能的突破
另一个重要发展领域是物理人工智能。在消费者科技盛会——2026年国际消费电子展(CES)上,NVIDIA首席执行官黄仁勋谈到了物理人工智能的“ChatGPT时刻”。与代理式人工智能类似,其技术突破点在于大语言模型的推理能力以及人工智能工厂,后者能够生成无限合成数据,弥补自动驾驶和工厂外机器人在现实世界数据方面的不足。
ChatGPT可以通过抓取互联网上的所有文本、图像和视频进行学习。但物理人工智能却缺乏类似可供学习的数据集,以理解重力、摩擦力和动量等现实世界的作用力,或应对现实世界中遇到的各种日常“边角案例”(即正常操作参数之外、涉及多重变量和条件的特殊情况)。
作为首批新一代人工智能驾驶算法平台之一,英国初创公司Wayve Technologies采用端到端学习模型而非传统的模块化规则驱动型驾驶系统。该公司认为,其软件能够在数周而非数年之内学习适应美国的驾驶环境,包括学会靠右行驶(英国为靠左行驶),并掌握不同的交通规则。由此,我们可以看到,自动驾驶出租车正在开展更广泛的测试与推广——Waymo计划在2026年底前覆盖美国大多数城市,并登陆伦敦和东京市场。与此同时,特斯拉以及小马智行和文远知行等中国企业也制定了宏伟的全球发展计划。
如今我们看到机器人动作愈发灵巧,既能表演霹雳舞和武术,又能执行更智能的任务,如将食品杂货放入冰箱等家务劳动。虽然相较于基于代理式人工智能的聊天机器人或自动驾驶领域取得的进展,人形机器人的发展稍显滞后,但也已展现出明确的发展前景。人们寄望于人形机器人能缓解我们面临的人口结构挑战——到2050年,大多数发达国家及中国的劳动适龄人口与老龄依赖人口(65岁以上)的比例将仅为约2:1。人形机器人正是一种人工智能机器人解决方案,能够为制造业、服务业以及日益增长的老年人群的照料工作提供所需的劳动力。
中国主动投资人工智能需意识到关键风险
作为投资者而非未来学家,我们始终在考量人工智能技术浪潮中的风险因素。我们从技术发展角度出发,进而关注融资问题,最终考量企业如何获得回报并实现商业化变现。作为投资者,我们时刻谨记这一构成我们投资理念与决策基石的核心原则:永远无法盈利的企业价值为零。
人工智能技术发展势头良好,但我们仍需持续动态评估规模定律是否持续有效,新技术突破能否持续催生下一代能力。鉴于近年来我们有目共睹的巨额资本支出、互联网泡沫的记忆以及对某些领域循环融资的担忧,市场对人工智能融资可持续性的关注理所应当。
然而,就为资本支出融资而言,我们今天所处的环境已截然不同。绝大多数人工智能资本支出来自美国超大规模云服务提供商(依靠利润、自由现金流及净现金资产负债表来支撑投入),以及企业和主权国家(政府),6他们构成了如今NVIDIA的主要客户群体。但我们认为,新兴初创企业的风险正在升高,而他们在未来几年的支出中将占据越来越大的比重。
尽管市场对融资和收入存在一些误解,但我们认为,在备受瞩目的新兴初创企业中,ChatGPT的创建者OpenAI风险最高。不过该公司似乎确实拥有实现数百亿美元收入的可靠路径,这赋予了其规模优势,使其在融资需求方面具备更强的灵活性。并且最近,该公司似乎在融资和收入方面采取了更为务实的策略,据报道,其已将未来四年的融资承诺从1.4万亿美元缩减至6,000亿美元。7与此同时,主要归功于Claude Code的成功,Anthropic似乎有望在2028年实现现金流转正。8
我们还关注到,那些需要外部融资的公司正持续获得融资渠道支持。Anthropic最近获得了新一轮融资,使其估值达到3,800亿美元8,而OpenAI则宣布了一轮高达1,100亿美元的巨额融资9,并可能在今年年底进行首次公开募股(IPO)。虽然部分融资交易确实属于循环融资,美国超大规模云服务提供商和NVIDIA均有意愿参与,但这些可能只占Anthropic和OpenAI未来资本支出和运营支出(云合同)承诺的一小部分。
NVIDIA也指出,从其预期将强劲增长的自由现金流中拿出一部分投资于一些领先的人工智能新创公司,并非不合理之举。与互联网时代不同——当时Facebook能够收购Instagram和WhatsApp,Google能够收购YouTube和安卓,当前更严格的监管环境不允许此类收购,因此入股相关公司成为次优选择。
人工智能泡沫:事实还是泡沫?
当今市场与2000年已有本质差异。1999年,约有20只科技大盘股涨幅突破900%,仅数月间便推动纳斯达克指数飙升近100%。10
图3:当前并非2000年——当人人都在警告泡沫存在时,泡沫反而难以形成
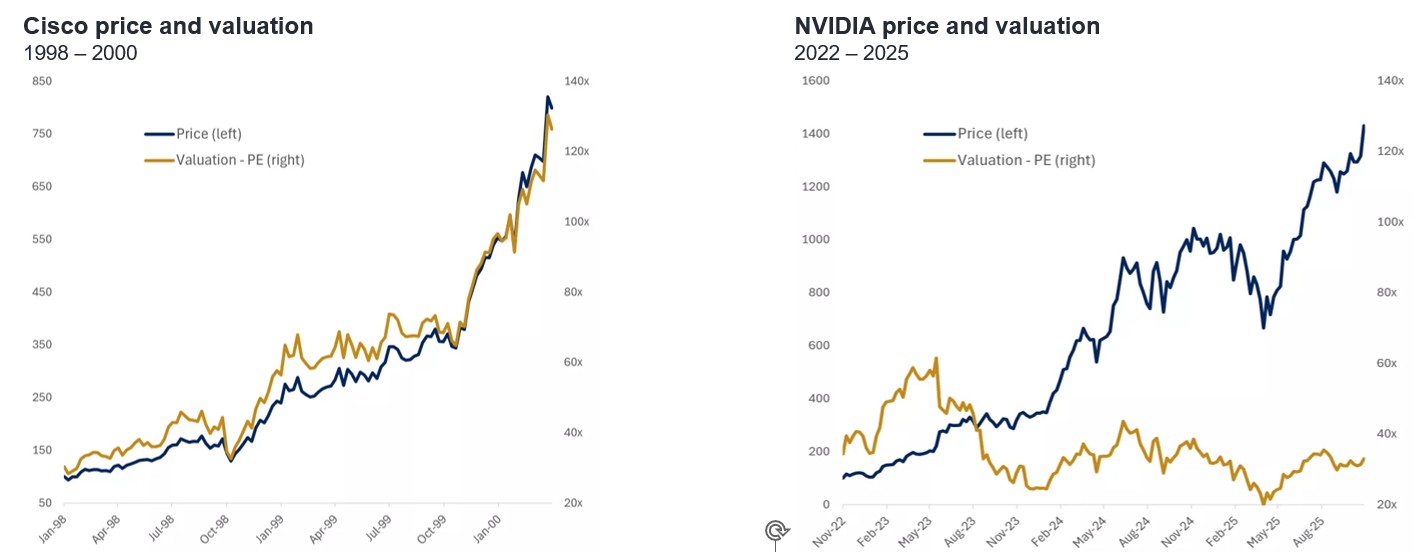
资料来源: 骏利亨德森投资、 FactSet 、Edward Jones,截至2025年9月30日。 注: 使用第三方名称、标识或徽标仅为说明目的,并未暗示任何第三方与骏利亨德森投资存在任何关联,亦不构成任何第三方的认可或推荐。除非另有说明,商标均为其各自所有者的专有财产。提及个别证券不构成对任何证券、投资策略或市场板块的买入、卖出或持有建议,亦不应被视为盈利保证。骏利亨德森投资、其关联顾问或其雇员可能持有所提及证券的头寸。风险敞口可能随时变更,恕不另行通知。
当时股价的剧烈波动主要源于估值因素,因为盈利增长并未同步跟上——例如Cisco的市盈率一度突破120倍(图3)。如今的情况截然不同,NVIDIA的预测市盈率约为25至30倍,与麦当劳(卖的是另一种“芯片”!——即“薯条”,英文同为chip)的估值相差无几!11当人人都在担忧泡沫、质疑人工智能能否兑现巨大预期以及资本支出可持续性时,泡沫反而难以形成。
我们此前已经强调,资本支出、应用增长与商业化变现之间始终存在时间差,这与互联网时代的经历如出一辙;可以理解的是,市场往往过于急躁。市盈率等股票估值指标反映的是市场观点而非事实,在科技领域,市场共识尤其可能出现重大偏差。我们认为,把握人工智能投资机遇的关键在于主动投资,发掘那些我们认为市场尚未充分认识其未来盈利增长潜力、因而当前估值相较于未来增长轨迹可能被低估的企业。
挑战在于,这是一个“赢家通吃”的行业,绝大多数利润将集中于少数几家公司。因此,投资于主题型交易所交易基金(ETF)的挑战在于,这类基金可能持有许多与标的主题毫无关联的股票;但更重要的是,其中许多公司可能永远无法从该主题中获得额外的利润增长,因而难以实现可持续增长。
作为团队,我们始终专注于发现意外的盈利增长机会——像人工智能这样的重大新技术浪潮或新主题是选股者的绝佳狩猎场,但我们认为,最佳投资结果很可能来自一个由真正赢家组成的高信念度投资组合,而非包含数百只股票的投资组合。
倘若英文版本与中文版本出现歧异,概以英文版为准。
1 Sequoiacap.com;《这就是AGI》;于2026年2月访问。
2 DarioAmodei.com,《技术的青春期》,2026年1月。
3 NVIDIA在GTC大会的演讲,2025年3月。
4 Gemini.google.com;《Gemini能做什么》;2026年3月2日访问。
5 Business Insider; ‘McKinsey CEO Bob Sternfels says the firm now has 60,000 employees: 25,000 of them are AI agents’; 12 January 2026.
6 Andreesen Horowitz领英帖文;《人工智能资本支出庞大但可持续》,2026年1月。
7 CNBC.com,《OpenAI调整支出预期,告知投资者其2030年算力支出目标约6,000亿美元》,2026年2月20日。
8 Forbes.com,《Anthropic:隐藏在明处的3,800亿美元巨头》,2026年2月13日。
9 FT.com; 《OpenAI达成创纪录融资协议,获1,100亿美元资金》;2026年2月27日。
10 高盛集团;《25年后回望:科技泡沫破裂的启示》;2025年3月27日。
11彭博;NVIDIA与麦当劳截至2026年2月26日的12个月预测市盈率对比。过往表现并非未来回报的预测。
智能体约束系统: 包裹在人工智能模型外层的软件基础设施,为智能体大脑提供运行所需的环境,包含工具集、记忆库及安全边界,使其能在现实世界场景中有效运作。
代理人工智能: 指能够运用复杂推理与迭代规划能力,自主解决多步骤复杂问题的人工智能系统。该系统通过整合来自多数据源及第三方应用的海量数据,自主分析复杂挑战、制定策略并执行任务。
资本支出: 企业为支持业务增长和扩张而推动新项目或投资时,用于重大长期资产支出的资金,此类资产包括不动产和设备(有形资产)或技术、软件、商标、专利等(无形资产)。
循环融资: 指市场对超大市值公司间人工智能基础设施投资的融资模式不具可持续性的担忧。在小范围公司集群内,相互关联的交易与投资意味着公司间彼此投资,资金接收方使用所获资本向原始投资方进行采购。若部分公司现金流不足,当企业估值过度膨胀时,这种模式可能引发泡沫风险,并对整体市场产生连锁影响。
端到端学习模型:与传统学习模型不同,端到端模型(通常为深度神经网络)在一个集成过程中同时处理学习任务,将原始输入数据(如图像、文本或音频)转化为目标输出(如分类、预测或动作)。
交易所交易基金(ETF):一种追踪指数、行业、大宗商品或资产组合(如指数基金)的证券。ETF在证券交易所像股票一样交易,其价格随标的资产价格涨跌而波动。与主动管理型基金相比,ETF的每日流动性通常更高,费用也更低。
Free cash flow: Cash that a company generates after allowing for day-to-day running expenses and capital expenditure. It can then use the cash to make purchases, pay dividends or reduce debt.
高信念度:指投资组合仅持有少数精选股票的策略,这些股票代表着基金经理认为最具超额回报潜力的机会。持仓数量较少意味着每只股票对投资组合的不佳/出色表现具有更大的影响力。高信念度策略可能导致波动性或风险加剧。
超大规模云服务提供商: 大规模提供云端、网络及互联网服务基础设施的公司。实例包括Google Cloud、Microsoft Azure、Facebook Infrastructure、阿里云及Amazon Web Services。
大语言模型(LLM): 一类专门的人工智能,经过大量文本进行训练,以理解现有内容并生成原创内容。
净现金:指通过从现金余额中扣除流动负债计算得出的公司流动性状况,包括可随时用于支付的高流动性资金。
物理人工智能:将复杂的人工智能算法整合至具象、可交互的系统中,使自主机器具备认知推理与空间感知能力,能从交互中学习并实时做出反应。典型应用包括自动驾驶车辆、外科手术机器人及人形机器人。
市盈率(P/E)一种股票常用估值指标,用于衡量股价与其每股盈利之间的比率。
推理模式: 利用现有资讯来产生预测、进行推断及得出结论的学习模型。该过程需将数据转化为机器可处理可理解的形式,再应用逻辑规则作出决策。
词元(token):人工智能标记是大语言模型(LLM)在输入和输出过程中使用的基本构建单元。它们是大语言模型用来处理和生成有效文本/输出的最小数据单位。